
Not if you have backed up your data. You have a backup of your data right?
Yeah the important stuff is backed up, but I am still concerned my entire OS will suddenly go kaput. How fucked am I?
The OS is the least important part of your computer.
It’d be bad if I were working on something and the entire thing just suddenly broke down before I have the time to save and backup 😅
If it’s your os drive that dies, nothing important has been lost except for a few minutes of work. You can boot from a variety of media (cd, usb…) for recovery, or drive replacement. Worst case, you’ll have to reinstall a few things in the following days.
If you have everything you need backed up you can reinstall on a new hard drive and restore everything you need. So you should not be completely fucked. Just an inconvenience you might have to go through. You will lose the stuff not backed up so if any of that is a pain to get again it might be more painful to restore everything.
Others have said some thing you might want to try. But having a spare disk you can swap to is never a bad idea. Disks to fail and you should plan for what to do when they do. Backing up your data is a good first step.
I would say it is not a bad idea to just get a new disk now and go through the process of restoring everything anyway - you can treat it like your disk has failed and do what you would need to do to restore. With the ability to swap back when you need to.
This is a good way to find things you might have missed in your backups.
- Back up your data now
- Reseat the cables for the drive
- Run a self test on the drive -
smartctl -t long- if it doesn’t pass, then the drive is trash. If it does, then it might limp along a bit longer before catastrophically failing
I used the GUI program for SMART and the list of issues got marked as “old age”, all of them.
Iirc old age is the best it can be
They meant the SMART self-test, not SMART data readout. Those are not meant to be interpreted by laymen and often not even experts.
I did perform the self-test function, the long version that says it will take 10s of minutes. Some of the errors were displayed with red text before the test. After the self test, it said that my drive passed and all the red errors showed up as “Old age” in black text, every single one.
(This is in the GUI app for smartctl)
Please stop trying to interpret the SMART data report. Even if you’re knowledgeable it can easily mislead you because this is vendor-specific data that follows no standard and is frequently misinterpreted by even the program displaying the data.
If the self-test passed, it’s likely the cable or the controller. Try a different cable.
Looks like either bad cable or failing drive.
What kind of machine is this, laptop? Desktop? If desktop, check the cables. Otherwise I’d switch out the drive.
You are probably fine. Check your cables as this is either buggy firmware or a flaky connection
No need to worry, disk failures almost never result in fires or hazardous conditions.
A-yuk-yuk-yuk.
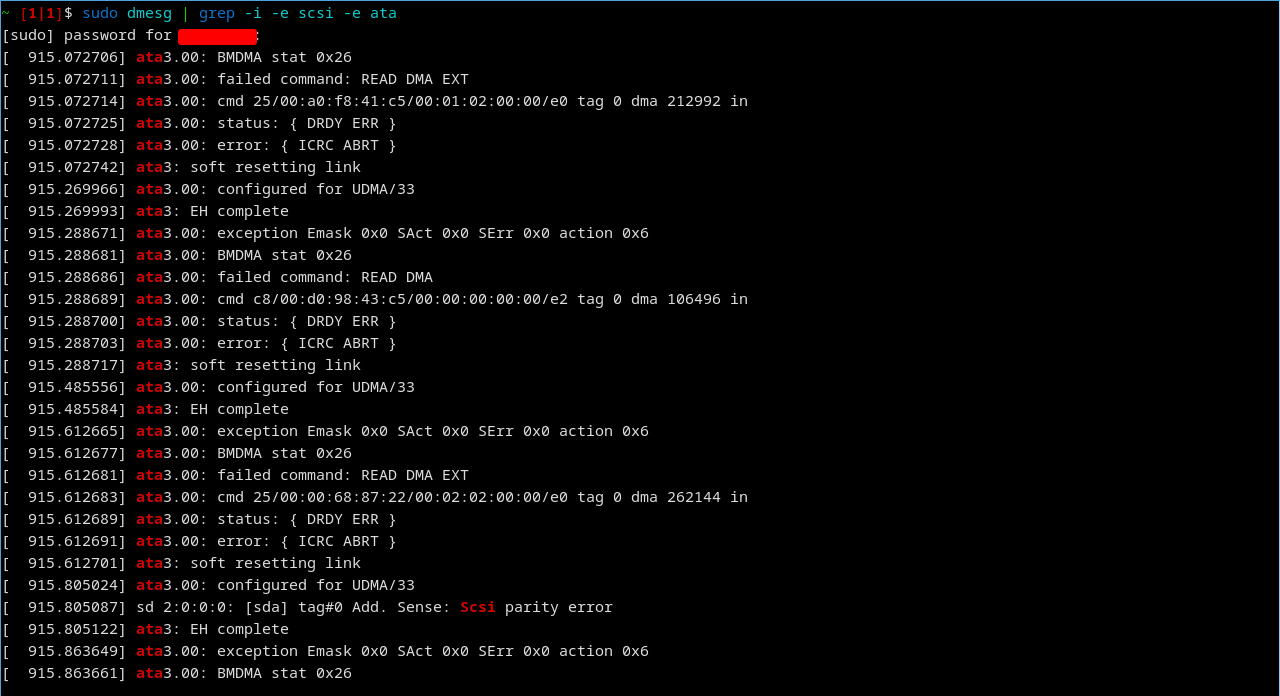
Seriously: you have a disk that has failed, based just on that little snippet of the logs, internally (ICRC ABRT). You can either use a tool like spinrite to try and repair it, but you may lose all the data in the process, or replace it.
A user suggested bad cabling and that’s a possibility, one you can check easily if the error is reproducible by swapping the cable. Before I swap cables often I’ll confirm the diagnosis using smartctl and look for whatever the drive manufacturer calls the errors that happen between the media and disk controller chip on the drive. If it has those then there’s no point in trying a cable swap, the problem is not happening there.
People will say that you can’t “fix” bad disks with tools like spinrite or smartctl. I’ve found that to be incorrect. There are certainly times when the disk is kaput but most of the time it’ll work fine and can go back into service.
Of course, that’s recovering from errors when I get an email or text the first time and going back to service in a multi-parity array so lowered criticality and early detection could have lots to do with that experience.
I have no idea what all of that is but it looks like something I would worry about. I’d say it’s time for a clean install and thinking of a new root password.
I’d say it’s time for a clean install and thinking of a new root password.
Huh? What has that to do with a possibly failing drive?
Because to me it looked like someone or something was trying to get access to root only features. I didn’t know it had anything to do with drives.
I too love talking about things I know nothing about.
Is this real? I feel like you are trolling
I am not trolling. I’m just very bad at finding information online.
First clue was the “ata” prefacing every error message. Then various things like “SCSI parity error” which indicates data corruption during transmission. “Parity” data is used to double check the integrity of the actual data.
It doesn’t tell anything to me. The only disk related thing I know is fsck.
I don’t get how you were able to arrive at that conclusion by looking at the console output, but sure, why not.
It’s the same error, no matter how many times I reinstall. I assume it’s a hardware issue
Can be a distro/setup issue as well. Also you should’ve added this info to your post. It’s very useful for troubleshooting the issue.








{kind=link}