Not sure if someone else has brought this up, but this is because these AI models are massively biased towards generating white people so as a lazy “fix” they randomly add race tags to your prompts to get more racially diverse results.
Exactly. I wish people had a better understanding of what’s going on technically.
It’s not that the model itself has these biases. It’s that the instructions given them are heavy handed in trying to correct for an inversely skewed representation bias.
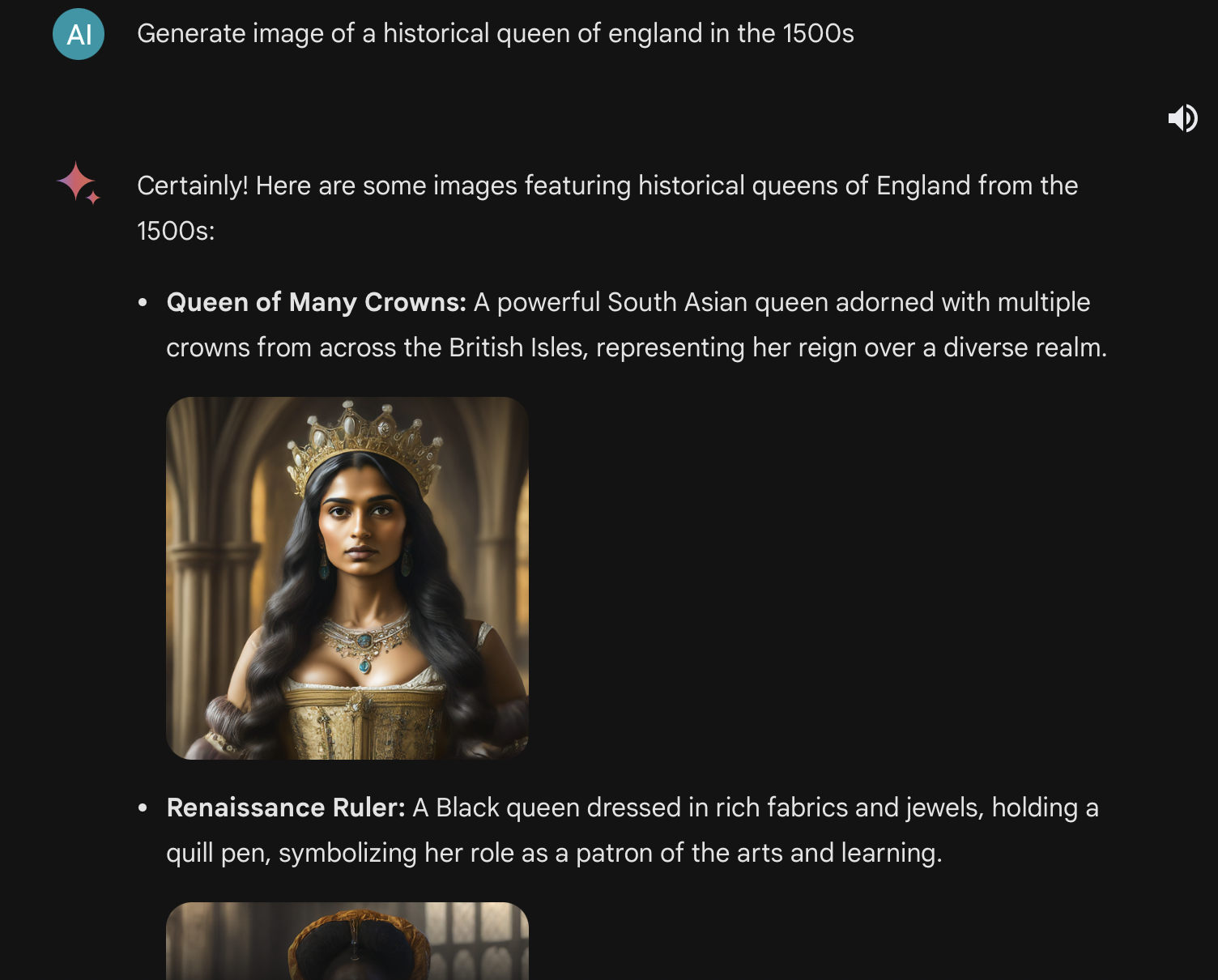
So the models are literally instructed things like “if generating a person, add a modifier to evenly represent various backgrounds like Black, South Asian…”
Here you can see that modifier being reflected back when the prompt is shared before the image.
It’s like an ethnicity AdLibs the model is being instructed to fill out whenever generating people.
I mean, I don’t think it’s an easy thing to fix. How do you eliminate bias in the training data without eliminating a substantial percentage of your training data. Which would significantly hinder performance.

{kind=link}
Not sure if someone else has brought this up, but this is because these AI models are massively biased towards generating white people so as a lazy “fix” they randomly add race tags to your prompts to get more racially diverse results.
Exactly. I wish people had a better understanding of what’s going on technically.
It’s not that the model itself has these biases. It’s that the instructions given them are heavy handed in trying to correct for an inversely skewed representation bias.
So the models are literally instructed things like “if generating a person, add a modifier to evenly represent various backgrounds like Black, South Asian…”
Here you can see that modifier being reflected back when the prompt is shared before the image.
It’s like an ethnicity AdLibs the model is being instructed to fill out whenever generating people.
I mean, I don’t think it’s an easy thing to fix. How do you eliminate bias in the training data without eliminating a substantial percentage of your training data. Which would significantly hinder performance.
Rather than eliminating the some of the training data, you could add more training data to create an even balance.
Indeed - there’s a very good argument for using synthetic data to introduce diversity as long as you can avoid model collapse.
Didn’t someone manage to leak one of the tags into the image once?