you can use something like smspool.net to verify the account with a one time use #. then google will allow you to link an authenticator app to the account. removing the # from the account afterwards does not remove the TOTP code either.
- 0 Posts
- 22 Comments
Joined 8 months ago
Cake day: March 18th, 2024
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
I got my 7a referbished for 350. the nothing phone is cool IMO but probably not going to have good support rn for nieche stuff. lineage & divest not having working versions for the phone raises red flags personaly.
if you are anti pixel & $500 is in your price range maybe take a look at the fairphone 4?
honestly I would personaly look into a used option just for pricing reasons. I think the 8 offered additional security benefits though. It may be a while until the 9 drops but that would also be an option.
if you want to degoogle the only way to run some apps without unprivileged code (GMS/microG) is to use grapheneos & its sandbox compatibility layer. this is unfortunately only available on the pixels.
I also worry you won’t be able to use some of the customization options that the nothing phone 2 offers with its hardware when using a custom ROM. if thats something u care about.
I have the pixel 7a & have had essentialy no issues with anything for what that’s worth.

 1·6 months ago
1·6 months agosession doesnt have perfect forward secrecy. they removed it from signals protocol to make it more easily compatible with their onion routing/crypto network. makes it one of the easiest apps to be “backdoored” if any keys were to be compromised.
there’s a foss flavor on the Fdroid repo that doesnt have any trackers I believe
oh I see interesting. seems like blatant malpractice to me. good luck on your paper o7
thank you 🙏
I meant that if you look at the “purpose” section of each cookie the ones that are older than 180 days are the only ones that dont mention advertising. thinking they may be related to the “nessecary” or “required” cookies that some websites have. I would presume they have their own or altered version of the other cookies policies since they have different purposes.
apologies, I worded that poorly before.
while I am by no means an expert on this, my gut tells me that this is probably something to do with “nessecary” cookies vs advertising & tracking cookies. its a common loophole for other policies so I wouldnt be surprised if they had some way of circumventing the normal limitations for tracking because of “fraud protection” or the likes.
looking at the cookie descriptors, all of the 1825 day cookies are used to “store &/or access information on device refreshes”. the shorter cookies are the only ones that also mention “measuring advertising & content performance”.
ahhh I see what you mean.
your thoughts on spacing out your connections & isolating is smart. unfortunately if you connect from the same device & browser any government agency or dedicated company with a big enough dataset (google, meta, etc.) would still be able to link you regardless of you IP by browser fingerprint alone. this does make YouTube more specifically being linked to your exact browser fingerprint porblamatic in a high stakes situation. As it, as you said is linked to your identity.
for lower level tracking changing IP regularly is effective. however, instead of switching to your local IP it would be more privacy conscious to just switch to a different VPN server.
unfortunately if you are genuinely worried about government level surveillance or the likes u enter into territory where VPNs often no longer cut it (or at least can’t truly be trusted too) as they are centralized & can be forced to make exceptions for law enforcement. traffic analysis is also easier, which makes time correlation deanonimization a more realistic risk when talking about government agencies specifically.
the tor + vpn debate is one that lots of people argue & is excedingly complicated. tor is generally more than enough, unless you are wanted by INTERPOL haha. if you are genuinely worried about suppressive government or world powers targeting you look further into tor, & do not connect directly to your ISP at all as that data is essentially up for grabs to local authorities (depending on locale).
for you specifically I would consider doing your more sensitive tasks in the tor browser without the VPN & then having your normal browser always on the VPN so they would be more difficult to correlate. anything torrent related is low enough stakes that I would imagine just about any proxy would suffice. hope this was helpful 🙏.
tldr; no, if you trust your vpn more than your ISP always use it, as any hit to fingerprinting is menial.
it really can’t hurt much to always be using it. any fingerprinting metric it would give is outweighed by the hiding of your IP behind the proxy. this is the #1 unique identifier that is tied back to people/locations.
the other fingerprinting metrics also are still exposed anyway & could probably be linked back to “you” regardless of your IP changing if they wanted too.
if you are worried about fingerprinting look into some projects like mullvad, librewolf, or even tor. clearing cookies on quit &/or having a separate browser for permenant logins/tokens to live in is also a good mitigation technique.
oh damn I see sorry u can’t get the apps to work I guess I’ll do a little digging on my side. in the mean time I hope I’ve been at least somewhat helpful haha 🙏
important second frame for context!
& no it isnt. quite sure twitter broke link previews a long time ago alongside guest accounts.
this is extremely scary if true. are these algorithms obtainable by every day people? do they work only in heavily photographed areas or do they infer based on things like climate, foliage, etc? I would love some documentation on these tools if anyone has any.
I would avoid trying to make sure you use the “official instance” as it kind of works against the projects purpose of decentralizing web requests. pinging around instances helps with avoiding outages as well. you can find active instances here on the uptime monitor.
otherwise, stealth should work just fine if u turn on webscraping mode. I have been using it since the reddit changes with only very occasional issues, as similar to you I have some quams with alternative reddit clients.
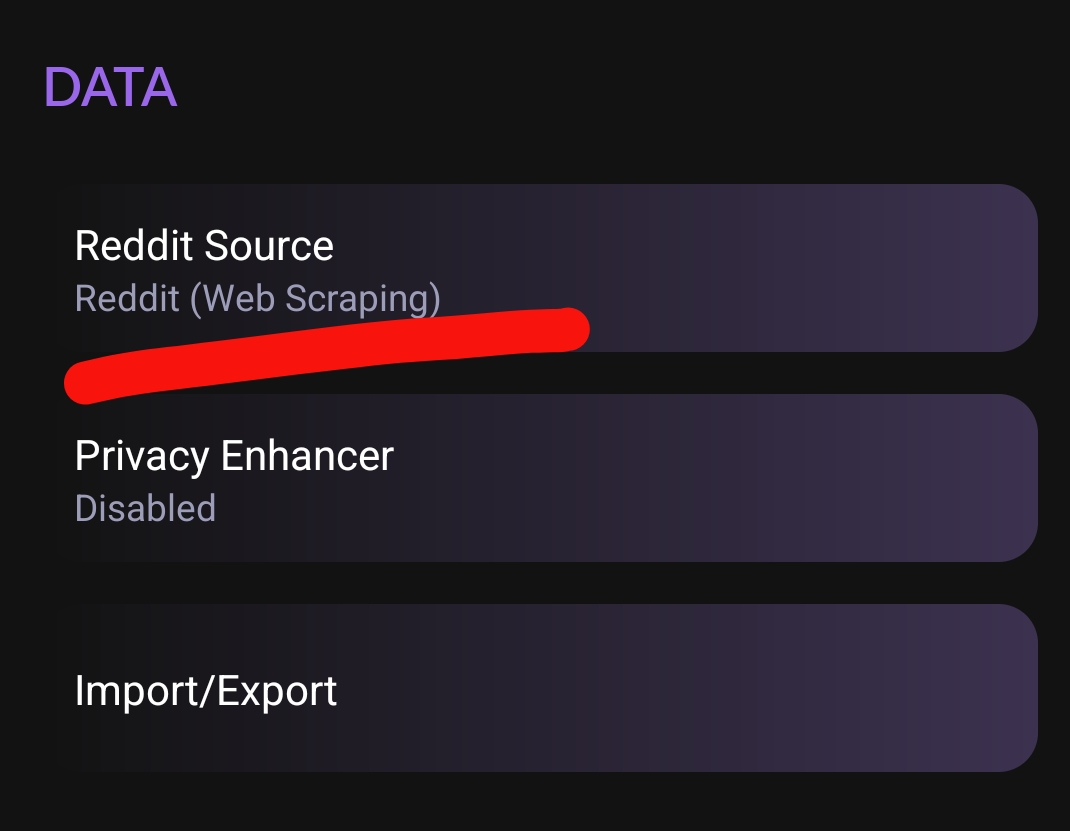
redlib is the updated version of libreddit & it seems to have circumvented the issues reddit caused so maybe consider giving it another try.
I think stealth also broke when they removed free API access. although, you can still use the webscraping mode by changing it in the settings I believe. if u want another option maybe try out RedReader or Geddit.
have you considered using alternatives front ends for some of the major social platforms?
I use libreddit/redlib to browse reddit. you can run an instance locally or connect to remote ones. this way your IP isn’t logged by reddit in the first place & no JavaScript is required to be run for the website to function properly.
there is even an extension called libredirect which can automatically swap clicked reddit (& other platforms) links to the same page on public frontends, which removes the hasstle of manually changing the URL.
unfortunately the blocking of servers is a perpetual battle that plauges almost any publicly listed proxy (vpns, tor, etc). the only way I have found around it is using lesser known/blocked VPNs or residential proxies. both of which probably have subpar data privacy policies, if they even follow them at all.
althought it likely won’t help your captcha troubles, I would like to give a huge +1 to mullvad. have been a happy customer for years. in compsrison to proton as a company they have a much more direct/benifitial effect on the web & furthuring users privacy online in my eyes.
scrambled exif is really practical & easy to use. it has been a player for a while now where as metadata remover seems newer & possibly less trustworthy/vetted because of it.
it also doesnt seem to add much new functionality from scrambled exif besides viewing data in app.
I personally use image toolbox which allows you to select what specific exif tags you would like to remove. however, I wouldnt put any more trust in its accuracy or comprehensiveness than any other adjacent app as they realistically all probably work very similarly.
if its imperitive you don’t leak any exif data I would recommend checking that in an external & more trusted app anyway. something like aves or a similar gallery that will lay out all all metadata tied to an image.
self hosting is the only way to guarantee logs arent shared.
however it also means that your server address only pulls requests for things YOU look at, not the whole pool of people using the server. imo this is a bad trade off as it would allow the services to track my browsing easily anyway.
personally I would recommend looking at libredirect with a large # of frontend instances selcted & a vpn/tor. these websites normally work without javascript, so assuming you have a privacy focused browser your IP is the only tracking metric they really have. spreading your requests out over different servers whilst using a proxy would make this really difficult to correlate as it would require that mutliple instance operators were malicious & collaborating.